Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 2Inference in Simple Linear Regression
The focus now shifts to statistical inference in the setting of a simple linear regression model applied to a data set containing the n data pairs [latex]( X_1, \, Y_1 ), \, ( X_2, \, Y_2 ), \, \ldots , \, ( X_n, \, Y_n )[/latex]. The statistical inference typically takes the form of confidence intervals and hypothesis tests concerning the various parameters in the simple linear regression model. More specifically, the sections that follow concern statistical inference concerning σ2, β1, β0, [latex]E[Y_h][/latex], [latex]Y_h^\star[/latex], and joint statistical inference concerning β0 and β1.
2.1 Simple Linear Regression with Normal Error Terms
Drawing mathematically tractable statistical inferences concerning the parameters in a simple linear regression model is not possible with the current assumptions given in Definition 1.1. The problem lies in the vagueness of the assumptions about the error term. The assumption in a simple linear regression model is that the error term ϵ is a random variable with population mean 0 and finite population variance σ2. The most common way of making this assumption more specific is to assume that the error term is normally distributed with population mean 0 and finite population variance σ2. This will be stated formally in the following definition.
Instead of just any probability distribution with a population mean of zero, we now specify that the error term should have a bell-shaped distribution centered about zero. Even though this is a more limiting assumption, it will allow us to establish exact confidence intervals and perform the associated hypothesis tests on the model parameters and other aspects of the model that might be of interest. Under this more restricted model, it is important to assure that the residuals (which estimate the error terms) do indeed have a bell-shaped distribution which has constant variance over the values of the independent variable in which the model is valid. Another way of stating Definition 2.1 is
Since this model is a special case of the simple linear regression model from Definition 1.1, all of the results from the previous chapter still apply to the simple linear regression model with normal error terms. As before, for the n data pairs [latex](X_1, \, Y_1), \, (X_2, \, Y_2), \, \ldots , \, ( X_n, \, Y_n )[/latex], the model becomes
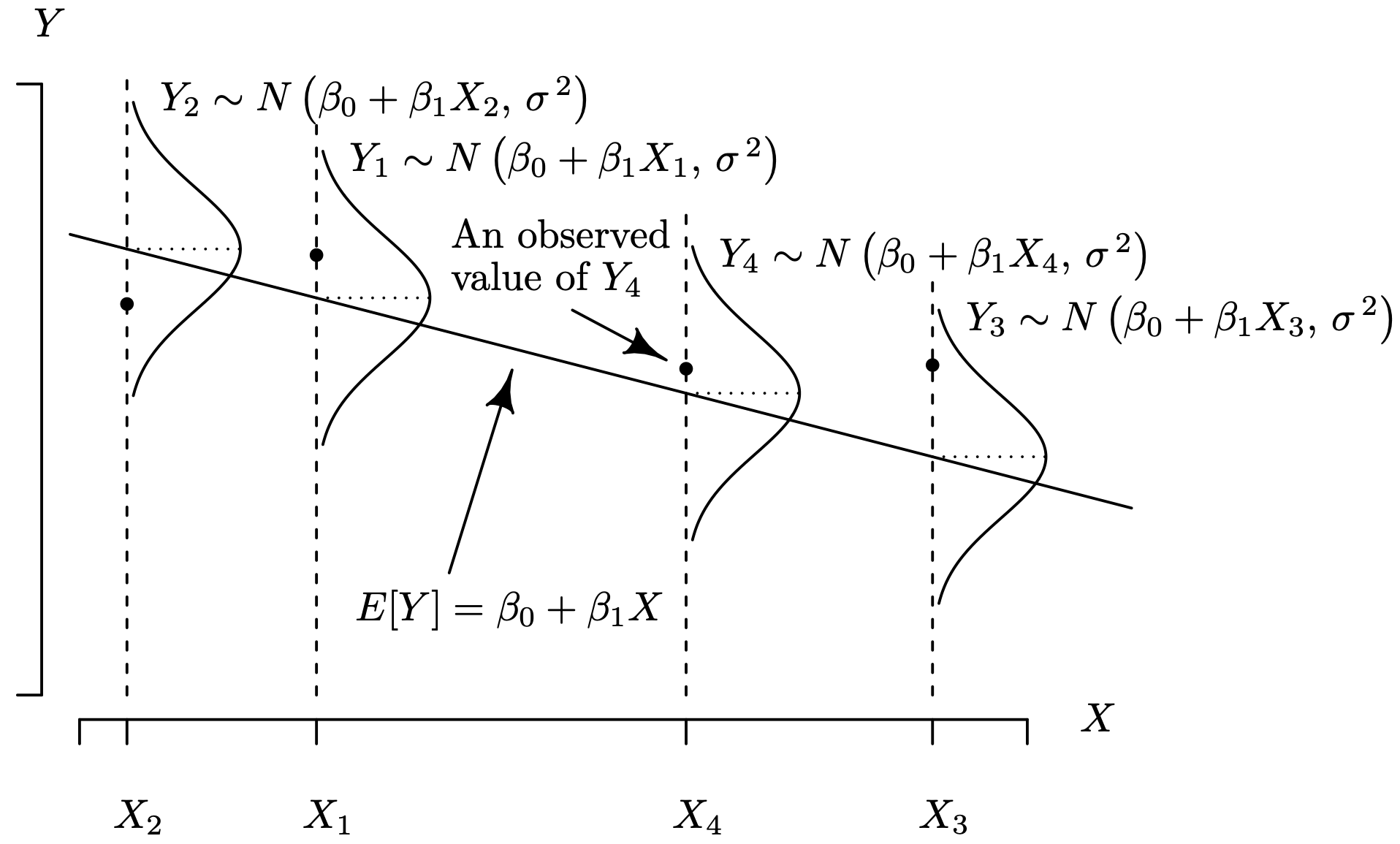
for [latex]i = 1, \, 2, \, \ldots, \, n[/latex], where [latex]\epsilon_1, \, \epsilon_2, \, \ldots , \, \epsilon_n[/latex] are mutually independent and identically distributed [latex]N\left(0, \, \sigma ^ {\, 2} \right)[/latex] random variables. The geometry associated with this model is shown in Figure 2.1. The model regression line (not the estimated regression line) [latex]E[Y] = \beta_0 + \beta_1 X[/latex] is shown with a negative slope. There are [latex]n=4[/latex] data pairs collected from this simple linear regression model with normal error terms. The probability density function of each of the Yi values, rotated clockwise by 90° highlights the fact that the population error distribution is normal with a population variance that does not change from one data pair to the next. The geometry illustrated here indicates how a simulation of a simple linear regression model with normal error terms is conducted. Once an Xi value has been established, a Yi value is generated as [latex]Y_i \sim N \left( \beta_0 + \beta_1 X_i, \, \sigma ^ {\, 2} \right)[/latex], for [latex]i = 1, \, 2, \, \ldots, \, n[/latex]. A realization of four data pairs [latex]\left( X_1, \, Y_1 \right), \, \left( X_2, \, Y_2 \right), \, \left( X_3, \, Y_3 \right), \, \left( X_4, \, Y_4 \right)[/latex] is given by the points plotted in Figure 2.1. The estimated regression line [latex]\hat{Y} = \hat \beta_0 + \hat \beta_1 X[/latex] can be calculated from these four data pairs in the usual fashion.
Figure 2.1:Simple linear regression model with normal error terms.Long Description for Figure 2.1
Four data pairs are plotted in the quadrant. A dotted vertical line from each of the data pairs is labeled X 2, X 1, X 4 and X 3, in the order from left to right, respectively. The line of regression with a negative slope is draw. The first data pair lies below the line of regression and the remaining lie above the line of regression. Probability density function, rotated 90 degrees clockwise, indicated at each of the Y intercept falling on the line of regression for X 2, X 1, X 4 and X 3 values show normal distribution. The equation for the line of regression is indicated as E of Y equals beta 0 plus beta 1 X. The equation above the dotted line X 2 reads, Y approximately equal to N, open parenthesis beta 0 plus beta 1 times X 2, sigma squared, close parenthesis. The equation above the dotted line X 1 reads, Y 1 approximately equal to N, open parenthesis, beta 0 plus beta 1 X 1, sigma squared, close parenthesis. The equation above the dotted line X 4 reads, Y 4 approximately equals N, open parenthesis, beta 0 plus beta 1 X 4, sigma squared, close parenthesis. The equation above the dotted line X 3 reads, Y 3 approximately equals N, open parenthesis, beta 0 plus beta 1 X 3, sigma squared, close parenthesis. The data pair on line X 4 is indicated as an observed value of Y 4.
2.2 Maximum Likelihood Estimators
Since we have now specified a parametric distribution for the error terms, maximum likelihood estimation can be used to determine parameter estimates for β0, β1, and σ2. As seen in the next result, the news is good. The maximum likelihood estimators for β0 and β1 are identical to the least squares estimators and the maximum likelihood estimator for σ2 differs from the associated least squares estimator by a constant factor.
The restriction that [latex]SSE > 0[/latex] in Theorem 2.1 is not a particularly restrictive assumption in practice. The only way to achieve a sum of squares for error of zero is to have all of the data pairs fall on a line. If this is indeed the case, then it is possible that a deterministic, rather than a statistical model, is appropriate.
The fact that the least squares estimators and maximum likelihood estimators for β0 and β1 are identical is welcome news. Since both techniques give the same values for [latex]\hat \beta_0[/latex] and [latex]\hat \beta_1[/latex], there is no lingering doubt as to which technique is appropriate for a particular modeling situation. But there is a slight difference between the estimators for σ2. In the previous section, the sum of squares for error was divided by the appropriate degrees of freedom to arrive at the following unbiased estimator for σ2:
or [latex]\hat{\sigma} ^ {\, 2} = SSE / (n - 2)[/latex]. On the other hand, the maximum likelihood estimator for σ2 uses a similar formula, but with an n rather than an [latex]n - 2[/latex] in the denominator. For large n, the difference is slight. But for small n, the difference can be significant. For the [latex]n = 3[/latex] sales data pairs first introduced in Example 1.3 with the variance of the error terms estimated in Example 1.10, for instance, the unbiased estimate of σ2 is [latex]\hat{\sigma} ^ {\, 2} = 14[/latex], whereas the maximum likelihood estimate of σ2 is [latex]\hat{\sigma} ^ {\, 2} = 14 / 3[/latex]. The standard practice in regression analysis is to use the unbiased estimator. In general, maximum likelihood estimators are not guaranteed to be unbiased, although they are consistent and asymptotically efficient. For the simple linear regression model with normal error terms, the maximum likelihood estimators for the slope and intercept are unbiased, but the maximum likelihood estimator for σ2 is biased.
In a more advanced course on regression, you will prove that the maximum likelihood estimators for the population intercept β0 and the population slope β1 (which are the same as the least squares estimators) are consistent, sufficient, and efficient. The property of consistency indicates that the estimators will converge to the associated population values as [latex]n \rightarrow \infty[/latex]; symbolically,
and
for any [latex]\delta > 0[/latex]. The property of sufficiency indicates that all of the information concerning the estimation of β0 and β1 is encapsulated in [latex]\hat \beta_0[/latex] and [latex]\hat \beta_1[/latex], respectively. The property of efficiency indicates that [latex]\hat \beta_0[/latex] and [latex]\hat \beta_1[/latex] have the smallest possible population variance among all unbiased estimators for β0 and β1, respectively.
2.3 Inference in Simple Linear Regression
Inference concerning the parameters in the simple linear regression model with normal error terms, which usually is performed in terms of constructing confidence intervals and performing hypothesis tests, is considered in this section. The following three subsections consider the sampling distributions of [latex]\hat \beta_0[/latex], [latex]\hat \beta_1[/latex], and [latex]\hat{\sigma}^{2}[/latex] under the simple linear regression model with normal error terms. We begin with σ2.
2.3.1 Inference Concerning σ2
Even though statistical inference concerning σ2 typically has the least interest of the three parameters in simple linear regression, there is an important result concerning the probability distribution of [latex]SSE / \sigma ^ {\, 2}[/latex] that is critical to the derivation of other results, so it is taken up first.
As an illustration of the use of Theorem 2.2, the derivation that follows develops an exact two-sided [latex]{100(1 - \alpha)}\%[/latex] confidence interval for σ2. Under the simple linear regression model with normal error terms, Theorem 2.2 states that
For some α value between 0 and 1, placing an area of [latex]\alpha / 2[/latex] in each tail of the chi-square distribution with [latex]n - 2[/latex] degrees of freedom gives
where the second value in the subscripts corresponds to right-hand tail probabilities. Rearranging the inequality to isolate σ2 in the center of the inequality gives an exact two-sided [latex]{100(1 - \alpha)}\%[/latex] confidence interval for σ2 as
This derivation is a proof of the following theorem.
2.3.2 Inference Concerning β1
In order to perform statistical inference concerning the population slope of the regression line β1, it is first necessary to establish the sampling distribution of the estimator [latex]\hat \beta_1[/latex]. Since the error terms [latex]\epsilon_1, \, \epsilon_2, \, \ldots , \, \epsilon_n[/latex] are mutually independent and identically distributed [latex]N\left( 0, \, \sigma ^ {\, 2} \right)[/latex] random variables under the simple linear regression model with normal error terms from Definition 2.1, the associated dependent variables [latex]Y_1, \, Y_2, \, \ldots, \, Y_n[/latex] are also mutually independent normally distributed random variables because [latex]Y_i = \beta_0 + \beta_1 X_i + \epsilon_i[/latex] for [latex]i = 1, \, 2, \, \ldots, \, n[/latex]. Furthermore, recall from Theorem 1.3 that [latex]\hat \beta_1[/latex] can be written as a linear combination of [latex]Y_1, \, Y_2, \, \ldots, \, Y_n[/latex] as
Since a linear combination of mutually independent normally distributed random variables is itself normally distributed, we can conclude that [latex]\hat \beta_1[/latex] is normally distributed.
Now that the normality of [latex]\hat \beta_1[/latex] has been established, the next step is to find the population mean and population variance of the point estimator [latex]\hat \beta_1[/latex], which will completely determine the distribution of [latex]\hat \beta_1[/latex]. From Theorem 1.2 and Theorem 1.4, the population mean and the population variance of the point estimator [latex]\hat \beta_1[/latex] are
The usual method for conducting statistical inference on a test statistic that is normally distributed is to subtract the population mean and divide by the population standard deviation. A problem that arises here is that the population variance of [latex]\hat \beta_1[/latex] in Theorem 2.4 is not known for a particular set of n data pairs because σ2 is not known. The population variance of [latex]\hat \beta_1[/latex], however, can be estimated by
where [latex]\hat{\sigma} ^ {\, 2} = MSE = SSE / (n - 2)[/latex], which is a quantity that can be estimated from n data pairs. We can now use
as a pivotal quantity in the following result.
Theorem 2.5 can be used to construct confidence intervals and perform hypothesis tests concerning β1. In many applications, β1 is the key parameter in the regression analysis because statistical evidence showing that it differs from zero indicates a linear relationship between X and Y if the assumptions associated with a simple linear regression model with normal error terms are met.
As an illustration, an exact two-sided [latex]{100(1 - \alpha)}\%[/latex] confidence interval for β1 is developed as follows. Theorem 2.5 states that
For some α between 0 and 1, placing an area of [latex]\alpha / 2[/latex] in each tail of the t distribution with [latex]n - 2[/latex] degrees of freedom gives
where the second value in the subscripts corresponds to right-hand tail probabilities. Rearranging the inequality to isolate β1 in the center of the inequality gives an exact two-sided [latex]{100(1 - \alpha)}\%[/latex] confidence interval for β1 as
where
This constitutes a derivation of the following theorem.
The hypothesis test concerning β1 with the null hypothesis
is based on the test statistic
which has the t distribution with [latex]n - 2[/latex] degrees of freedom under H0 and the simple linear regression model with normal errors. The most common value for [latex]\beta_1^\star[/latex] in the null hypothesis is [latex]\beta_1^\star = 0[/latex], which tests whether the estimated slope of the regression line [latex]\hat \beta_1[/latex] differs significantly from zero. This type of hypothesis test concerning β1 will be illustrated later in this chapter.
2.3.3 Inference Concerning β0
In order to perform statistical inference concerning the population intercept of the regression line β0, it is first necessary to establish the sampling distribution of [latex]\hat \beta_0[/latex].
Since the error terms [latex]\epsilon_1, \, \epsilon_2, \, \ldots , \, \epsilon_n[/latex] are mutually independent and identically distributed [latex]N\left( 0, \, \sigma ^ {\, 2} \right)[/latex] random variables under the simple linear regression model with normal error terms from Definition 2.1, the associated dependent variables [latex]Y_1, \, Y_2, \, \ldots, \, Y_n[/latex] are also mutually independent normally distributed random variables. Furthermore, recall from Theorem 1.3 that [latex]\hat \beta_0[/latex] can be written as a linear combination of [latex]Y_1, \, Y_2, \, \ldots, \, Y_n[/latex] as
Since a linear combination of mutually independent normally distributed random variables is itself normally distributed, we can conclude that [latex]\hat \beta_0[/latex] is normally distributed.
Now that the normality of [latex]\hat \beta_0[/latex] has been established, the next step is to find the population mean and population variance of the point estimator [latex]\hat \beta_0[/latex], which will completely determine the distribution of [latex]\hat \beta_0[/latex]. From Theorem 1.2 and Theorem 1.4, the population mean and the population variance of the point estimator [latex]\hat \beta_0[/latex] are
The usual method for conducting statistical inference on a test statistic that is normally distributed is to subtract the population mean and divide by the population standard deviation. A problem that arises here is that the population variance of [latex]\hat \beta_0[/latex] in Theorem 2.7 is not known for a particular set of n data pairs because σ2 is not known. The population variance of [latex]\hat \beta_0[/latex], however, can be estimated by
where [latex]\hat{\sigma} ^ {\, 2} = MSE = SSE / (n - 2)[/latex], which is a quantity that can be estimated from n data pairs. We can now use
as a pivotal quantity in the following result.
Theorem 2.8 can be used to construct confidence intervals and perform hypothesis tests concerning β0. In many applications, there is an interest in whether β0 is statistically different from 0. The results of this hypothesis test and the particular setting for the simple linear regression model indicate whether forcing a simple linear regression model through the origin is appropriate.
As an illustration, an exact two-sided [latex]{100(1 - \alpha)}\%[/latex] confidence interval for β0 is developed as follows. Theorem 2.8 states that
For some α between 0 and 1, placing an area of [latex]\alpha / 2[/latex] in each tail of the t distribution with [latex]n - 2[/latex] degrees of freedom gives
where the second value in the subscripts corresponds to right-hand tail probabilities. Rearranging the inequality to isolate β0 in the center of the inequality gives an exact two-sided [latex]{100(1 - \alpha)}\%[/latex] confidence interval for β0 as
where
This constitutes a derivation of the following theorem.
The hypothesis test concerning β0 with the null hypothesis
is based on the test statistic
which has the t distribution with [latex]n - 2[/latex] degrees of freedom under H0 and the simple linear regression model with normal errors. The most common value for [latex]\beta_0^\star[/latex] in the null hypothesis is [latex]\beta_0^\star = 0[/latex], which is for testing whether the estimated intercept of the regression line [latex]\hat \beta_0[/latex] differs significantly from zero. The p-value associated with this hypothesis test and the context associated with the meaning of X and Y might influence a modeler whether or not to fit a simple linear regression model which is forced through the origin.
2.3.4 Inference Concerning
Many applications of simple linear regression require not only point and interval estimates for the regression parameters β0, β1, and σ2, but also a point and interval estimate for the expected value of Y associated with a particular value of X. In this context, the simple linear regression model is being used to forecast the conditional expected value of Y from the data pairs. Denote the X-value of interest by Xh, which is a fixed constant that is observed without error within the scope of the simple linear regression model. The associated random Y-value is denoted by Yh, which has conditional expected value [latex]E[Y_h][/latex]. This compact notation for the conditional expected value is adopted over the more precise [latex]E[Y_h \, | \, X = X_h][/latex]. If the parameters β0 and β1 are known, then the point estimator for [latex]E[Y_h][/latex] is
which is simply the height of the population regression line at Xh. In nearly all applications, however, we estimate the parameters β0, β1, and σ2 from the data pairs [latex]\left( X_1, \, Y_1 \right), \, \left( X_2, \, Y_2 \right), \, \ldots , \, \left( X_n, \, Y_n \right)[/latex]. In this case, the point estimator for [latex]E[Y_h][/latex] is
which is simply the height of the estimated regression line at Xh. When the data pairs [latex]\left( X_1, \, Y_1 \right), \left( X_2, \, Y_2 \right), \dots, \left( X_n, \, Y_n \right)[/latex] are tightly clustered about the regression line, we expect a fairly precise point estimate for [latex]E[Y_h][/latex]. A more explicit notation for [latex]\hat{Y} _ h[/latex] is [latex]\hat E [ Y_h \, | \, X = X_h ][/latex] or [latex]\hat{\mu} _ {Y_h \, | \, X = X_h}[/latex]. We opt for the more compact [latex]\hat{Y}_h[/latex] and leave it to the reader to mentally convert this to the more explicit meaning.
The value of Xh might correspond to one of [latex]X_1, \, X_2, \, \ldots, \, X_n[/latex], or might correspond to another value of X. It is critical that Xh fall in the scope of the simple linear regression model. If Xh is less than [latex]\min \left\{ X_1, \, X_2, \, \ldots, \, X_n \right\}[/latex] or greater than [latex]\max \left\{ X_1, \, X_2, \, \ldots, \, X_n \right\}[/latex], then there should be some evidence, perhaps evidence based on data sets collected previously or evidence provided by experts in the subject matter, that the relationship between X and Y remains linear outside of the scope of the data pairs. Without evidence of this nature, one should not extrapolate beyond the scope of the simple linear regression model.
With the point estimator for [latex]E[Y_h][/latex] established, we now seek a pivotal quantity which can be used to construct confidence intervals and perform hypothesis tests concerning [latex]E[Y_h][/latex]. We continue to assume that the simple linear regression model with normally distributed error terms is appropriate. Recall from Theorem 1.3 that [latex]\hat \beta_0[/latex] and [latex]\hat \beta_1[/latex] can be written as written as linear combinations of [latex]Y_1, \, Y_2, \, \ldots, \, Y_n[/latex]:
and
for constants [latex]c_1, \, c_2, \, \ldots, \, c_n[/latex] and [latex]a_1, \, a_2, \, \ldots, \, a_n[/latex]. Furthermore, [latex]Y_1, \, Y_2, \, \ldots, \, Y_n[/latex] are mutually independent random variables because [latex]\epsilon_1, \, \epsilon_2, \, \ldots, \, \epsilon_n[/latex] are mutually independent random variables in the simple linear regression model [latex]Y_i = \beta_0 + \beta_1 X_i + \epsilon_i[/latex] for [latex]i = 1, \, 2, \, \ldots, \, n[/latex]. This implies that [latex]\hat{Y} _ h[/latex] can be written as
Since a linear combination of mutually independent normally distributed random variables is itself normally distributed, [latex]\hat{Y} _ h[/latex] is normally distributed under the simple linear regression model with normal error terms.
Now that the normality of [latex]\hat{Y} _ h[/latex] has been established, we seek its population mean and population variance, which will completely define its probability distribution. Since [latex]\hat \beta_0[/latex] and [latex]\hat \beta_1[/latex] are unbiased estimators of β0 and β1, respectively, the population mean of [latex]\hat{Y} _ h[/latex] is
via Theorem 1.2. So the point estimator [latex]\hat{Y}_h = \hat \beta_0 + \hat \beta_1 X_h[/latex] is an unbiased estimator of [latex]{Y_h = \beta_0 + \beta_1 X_h}[/latex]. Next, we calculate the population variance of [latex]\hat{Y} _ h[/latex]. Since [latex]\bar Y[/latex] and [latex]\hat \beta _ 1[/latex] are independent random variables (this was shown in the derivation prior to the establishment of the variance–covariance matrix of [latex]\hat \beta_0[/latex] and [latex]\hat \beta_1[/latex] in Theorem 1.4),
using the lower-right hand entry in the variance–covariance matrix for [latex]\hat \beta_0[/latex] and [latex]\hat \beta_1[/latex] from Theorem 1.4. This constitutes a derivation of the following result.
The population variance of [latex]\hat{Y} _ h[/latex] in Theorem 2.10 is of particular interest. If the experimenter has complete control over the choice of the values of the independent variables [latex]X_1, \, X_2, \, \ldots, \, X_n[/latex] in the data pairs [latex]\left( X_1, \, Y_1 \right), \, \left( X_2, \, Y_2 \right), \, \ldots , \, \left( X_n, \, Y_n \right)[/latex], the best choice is to (a) choose [latex]X_1, \, X_2, \, \ldots, \, X_n[/latex] so that [latex]S_{XX}[/latex] is as large as possible (that is, spread the [latex]X_1, \, X_2, \, \ldots, \, X_n[/latex] out as much as possible), and (b) choose [latex]X_1, \, X_2, \, \ldots, \, X_n[/latex] such that [latex]\bar X[/latex] equals Xh. These choices for the values of the independent variables will result in the smallest possible population variance for [latex]\hat{Y} _ h[/latex].
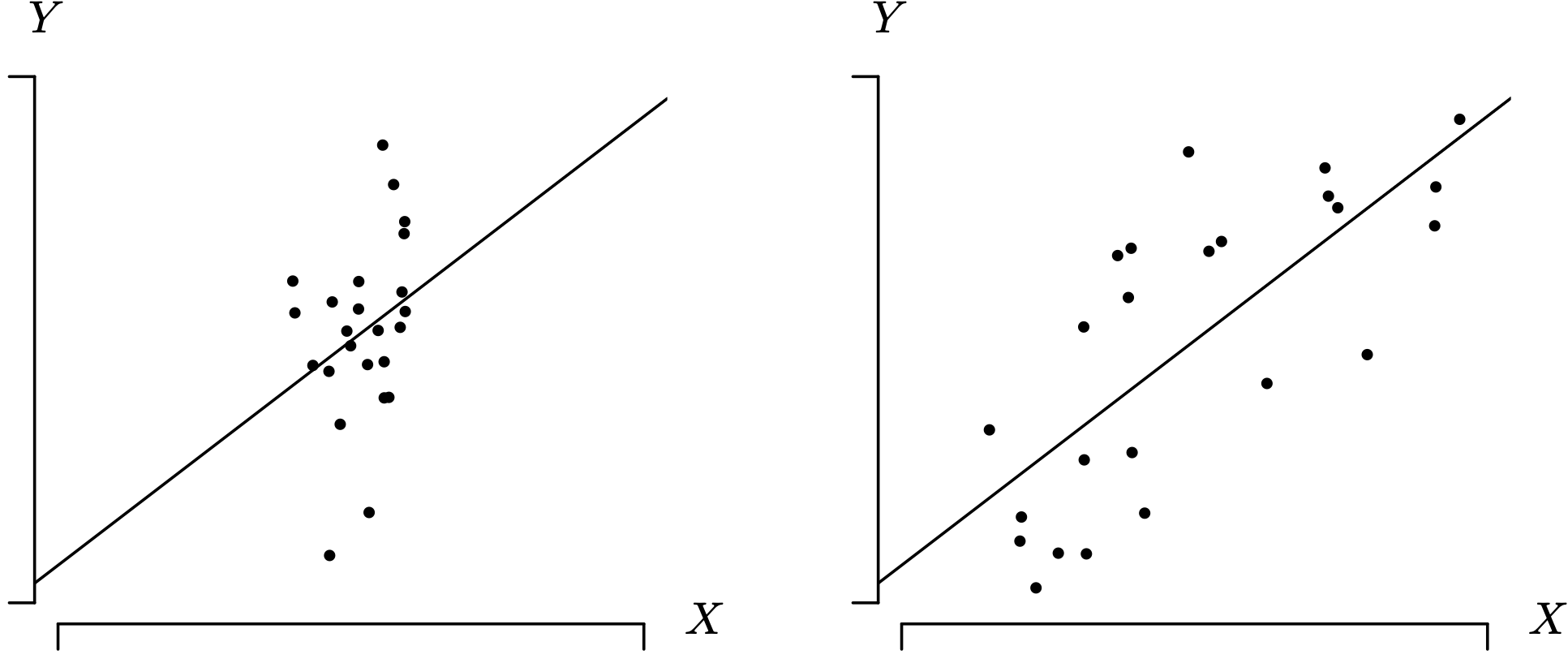
The geometry associated with the choice of the [latex]X_1, \, X_2, \, \ldots, \, X_n[/latex] values is illustrated in Figure 2.2. In each of the two scatterplots, there are [latex]n = 24[/latex] simulated data pairs drawn from simple linear regression models with normal error terms having identical population parameters β0, β1, and σ2.
Figure 2.2:The effect of spreading [latex]X_1, \, X_2, \, \ldots, \, X_n[/latex].Long Description for Figure 2.2
In both the scatter plot graphs, the horizontal axis is labeled X, and the vertical axis is labeled Y. Left graph: 24 data points plotted on the X Y place are clustered around center of the diagonal line with a positive slope. 10 points fall above, and 10 below the diagonal line. 4 points are on the diagonal line. Right graph: 24 data points plotted on the X Y plane are spread out along the diagonal line with a positive slope. 12 points are above the diagonal line, and 12 are below the diagonal line.
Although they are not labeled, the axes on the two graphs have identical scales, and the two regression lines have nearly the same slope and intercept. The key difference between the two graphs is that the values of the independent variable are less spread out in the left-hand graph and more spread out in the right-hand graph. The spread of [latex]X_1, \, X_2, \, \ldots, \, X_n[/latex] results in three conclusions. First, the scope of the regression model is narrower in the graph on the left. Second, the estimation of β1 is less stable when [latex]X_1, \, X_2, \, \ldots, \, X_n[/latex] are tightly clustered as in the graph on the left. Third, inference on [latex]E[Y_h][/latex] will be less precise in the graph on the left because the variance of [latex]\hat{Y} _ h[/latex] is larger via Theorem 2.10.
The development of a pivotal quantity for statistical inference concerning [latex]E[Y_h][/latex] follows along the same line of reasoning as that for β1 and β0. We can’t calculate the population variance of [latex]\hat{Y} _ h[/latex] from n data pairs because the value of σ2 is unknown, so it is estimated by
where [latex]\hat{\sigma} ^ {\, 2} = MSE = SSE / (n - 2)[/latex], which is a quantity that can be estimated from n data pairs. We can now use
as a pivotal quantity in the following result.
The proof of this result is analogous to the associated proofs for the pivotal quantities for inference concerning β0 and β1. This pivotal quantity can be used as a test statistic when conducting a hypothesis test concerning [latex]E[Y_h][/latex]. Proceeding in an analogous fashion to the development of the confidence intervals for β1 and β0, an exact two-sided [latex]{100(1 - \alpha)}\%[/latex] confidence interval for [latex]E[Y_h][/latex] is given next.
The calculation of an exact two-sided confidence interval for [latex]E[Y_h][/latex] from a data set consisting of n data pairs [latex]\left( X_1, \, Y_1 \right), \, \left( X_2, \, Y_2 \right), \, \ldots , \, \left( X_n, \, Y_n \right)[/latex] using Theorem 2.12 will be illustrated in the next example.
2.3.5 Inference Concerning
The previous section considered statistical inference on the mean response associated with a value Xh for the independent variable associated with the data pairs [latex]\left( X_1, \, Y_1 \right), \, \left( X_2, \, Y_2 \right), \, \ldots , \, \left( X_n, \, Y_n \right)[/latex]. This section considers statistical inference associated with the introduction of a new data pair. The value of the independent variable for this new data pair is, as before, Xh, which is a fixed constant observed without error within the scope of the model. We would like to perform some type of statistical inference on the associated value of the dependent variable [latex]Y_h^\star[/latex]. The star superscript is to denote that this is an additional data pair that is not one of the original n data pairs used to fit the simple linear regression model. There is a similar, but fundamentally different, analysis that must be used when we would like to consider the introduction of an additional data pair
Three examples in which this type of analysis is appropriate are given below.
A sociologist collects the [latex]n = 50[/latex] data pairs [latex]\left( X_1, \, Y_1 \right), \, \left( X_2, \, Y_2 \right), \, \ldots , \, \left( X_{50}, \, Y_{50} \right)[/latex], where the independent variable X is the wife’s height and the dependent variable Y is the husband’s height for 50 married couples. These data pairs represent 50 couples surveyed by the sociologist. If the sociologist knows the height of a married woman who is not in the group of 50, what statistical inference can the sociologist make about her husband’s height?
An economist collects the [latex]n = 50[/latex] data pairs [latex]\left( X_1, \, Y_1 \right), \, \left( X_2, \, Y_2 \right), \, \ldots , \, \left( X_{50}, \, Y_{50} \right)[/latex], where the independent variable is the average annual unemployment rate and the dependent variable is the annual gross domestic product (GDP) for a particular country. If these data pairs represent the last 50 years of data, and the economist knows the average annual unemployment rate for next year, what statistical inference can the economist perform on the random GDP for next year?
An engineer collects the [latex]n = 50[/latex] data pairs [latex]\left( X_1, \, Y_1 \right), \, \left( X_2, \, Y_2 \right), \, \ldots , \, \left( X_{50}, \, Y_{50} \right)[/latex], where the independent variable is the speed of a car and the dependent variable is the car’s stopping distance for 50 different cars. If the engineer knows the speed of a 51st car to be tested, what statistical inference can the engineer perform on its random stopping distance?
The common thread that runs through the three examples is that there is a new data pair, [latex]\left( X_{51}, \, Y_{51} \right) = \left( X_h , \, Y_h^\star \right)[/latex], that is being introduced.
So we would like to predict the outcome for a new value of the dependent variable associated with the new value of the independent variable, namely Xh. As before, the value of Xh need not necessarily correspond to one of the [latex]X_1, \, X_2, \, \ldots, \, X_n[/latex] values, but needs to fall within the scope of the model unless there is some prevailing evidence to make statistical inference outside of the scope of the model. In order to help frame the issues associated with the case of a new data pair being introduced, the next paragraph considers the very rare case in which all of the parameters in the simple linear regression model are known.
Consider the simplest case in which all parameters are known in the simple linear regression model. In the previous section, Theorem 2.12 gave a confidence interval for [latex]E \left[ Y_h \right][/latex], which is a fixed constant. In this section, we desire a statistical interval for [latex]Y_h^\star[/latex], which is a random variable. Because of this fundamental difference in the nature of [latex]E \left[ Y_h \right][/latex] and [latex]Y_h^\star[/latex], the interval derived here for [latex]Y_h^\star[/latex] is a prediction interval. If all of the parameters in the regression model are known, Definition 2.1 indicates that
Standardizing this normally distributed random variable,
The probability that this standard normal random variable lies between the [latex]\alpha / 2[/latex] and [latex]1 - \alpha / 2[/latex] fractiles of the standard normal distribution is
Some algebra on the inequality gives an exact two-sided [latex]{100(1 - \alpha)}\%[/latex] prediction interval for [latex]Y_h^\star[/latex] as
Although this derivation is straightforward, the vast majority of regression applications do not have parameters which are known a priori, and we now pivot to the more practical question.
In the case in which the parameters in the simple linear regression model are unknown, they must be estimated from the n data pairs. The point estimator for [latex]Y_h^\star[/latex] is the same as the point estimator in the previous section:
Handling the population variance of [latex]Y_h^\star[/latex] requires a little more finesse. In the case of the parameters being estimated from n data pairs, the population variance of [latex]Y_h^\star[/latex] comes from two sources:
the population variance associated with a new observation of the dependent variable, and
the population variance induced by estimating the intercept and slope of the fitted regression line from the n data pairs.
Since the new data pair is independent of the original n data pairs, the population variance of the prediction error is
Since [latex]\hat{Y} _ h[/latex] is normally distributed via Theorem 2.10 and [latex]Y_h^\star[/latex] is independent of [latex]\hat{Y} _ h[/latex] and is also normally distributed, we have the following result.
The population mean of the normal distribution in Theorem 2.13 is estimated by
and the population variance of the normal distribution is estimated by
Using an analogous approach to the pivotal quantities in the previous sections, the following quantity can be used for statistical inference concerning [latex]Y_h^\star[/latex].
The proof of this result is analogous to the associated proofs for the pivotal quantities for inference concerning β0 and β1. This pivotal quantity can be used as a test statistic when conducting a hypothesis test concerning [latex]Y_h^\star[/latex]. Proceeding in an analogous fashion to the development of the confidence intervals for β1 and β0, an exact two-sided [latex]{100(1 - \alpha)}\%[/latex] prediction interval for [latex]Y_h^\star[/latex] is given next.
Adding a 1 inside of the expression for [latex]\hat{V} \big[ \hat{Y}_h^{\kern 0.15em \star} \big][/latex] ensures that the prediction interval for [latex]\hat{Y} _ h[/latex] will be wider than the associated confidence interval for [latex]E[ Y_h ][/latex] from Theorem 2.12. In both results, the intervals are narrowest when Xh is near [latex]\bar X[/latex] and the observations of the independent variable are spread out so as to maximize [latex]S_{XX}[/latex].
A thought experiment that helps clarify the difference between the confidence interval for [latex]E[Y_h][/latex] and the prediction interval for [latex]\hat{Y}_h^{\kern 0.15em \star}[/latex] is to consider the two intervals associated with [latex]X_h = \bar X[/latex]. A careful inspection of the confidence interval given in Theorem 2.12 indicates that the width of the confidence interval for [latex]E[Y_h][/latex] approaches zero as [latex]n \rightarrow \infty[/latex]. Increasing the number of data pairs without bound results in perfect precision for the point estimator for the conditional expected value [latex]\hat{Y}_h = \hat \beta_0 + \hat \beta_1 X_h[/latex]. On the other hand, a careful inspection of the prediction interval given in Theorem 2.15 indicates that the width of the prediction interval for [latex]\hat{Y}_h^{\kern 0.15em \star}[/latex] approaches a finite, nonzero value as [latex]n \rightarrow \infty[/latex]. When a new observation associated with independent variable [latex]X_h = \bar X[/latex], the associated point estimator for the conditional expected value of the dependent variable [latex]\hat{Y}_h^{\kern 0.15em \star} = \hat \beta_0 + \hat \beta_1 X_h[/latex] has a population variance that approaches the MSE (which, in turn, approaches σ2) as [latex]n \rightarrow \infty[/latex]. It is not possible to predict the random response to a new data pair with perfect precision.
This section and the previous four sections have introduced various techniques for statistical inference in the setting of a simple linear regression model with normal error terms. Table 2.1 summarizes many of the key results from these sections. The first column gives the parameter of interest. The second column gives the pivotal quantity and its distribution. This pivotal quantity serves as the test statistic in a hypothesis test concerning the parameter of interest. The third column gives an exact two-sided [latex]{100(1 - \alpha)}\%[/latex] confidence interval for the parameter of interest for the first four rows and an exact two-sided [latex]{100(1 - \alpha)}\%[/latex] prediction interval for the parameter of interest for the last row.
Table 2.1:Pivotal quantities and exact statistical intervals for a simple linear regression model.
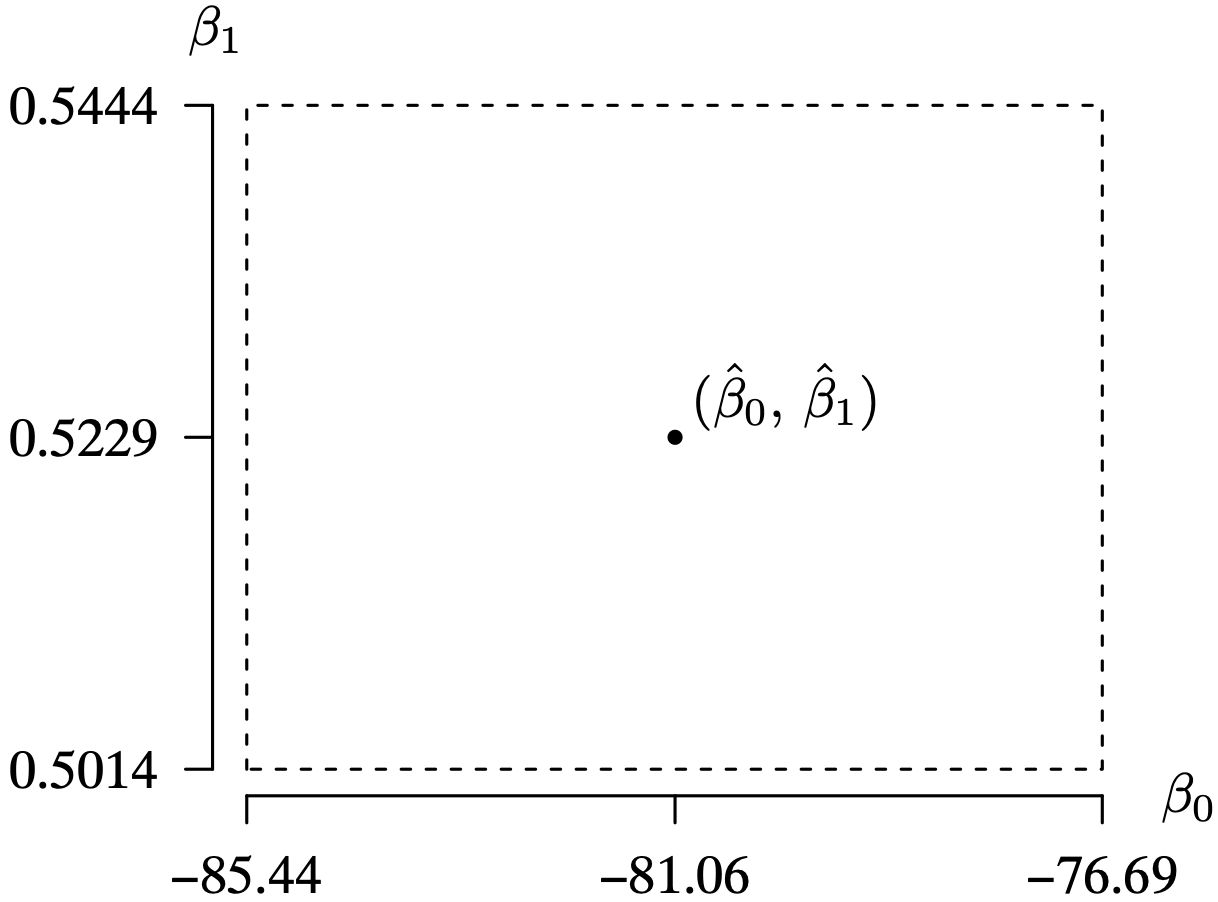
The exact two-sided [latex]{100(1 - \alpha)}\%[/latex] confidence intervals for the intercept β0 and slope β1 in a simple linear regression model with normal error terms developed in Sections 2.3.2 and 2.3.3 might be combined to provide a joint confidence region on both parameters. Occasions arise in regression modeling in which joint inference on both β0 and β1 simultaneously is required. As a particular instance, recall from Examples 2.2 and 2.3 that the unbiased point estimators for β0 and β1 for the Forbes data set were
and the associated exact two-sided 95% confidence intervals for β0 and β1 calculated separately were
The union of these two confidence intervals is depicted by the rectangle in Figure 2.5. The point estimates for β0 and β1 are depicted by the point at the center of the rectangle. Does the union of the two confidence intervals depicted by the rectangle in Figure 2.5 constitute an exact 95% confidence region for β0 and β1? It does not. The problems associated with this rectangular-shaped confidence region are outlined in the next two paragraphs.
Figure 2.5:Confidence region for β0 and β1. Long Description for Figure 2.5
The horizontal axis is labeled beta 0 and ranges from negative 85.44 to negative 76.969 in increments of 4.38. The vertical axis labeled beta 1 and ranges from 0.5014 to 0.5444 in increments of 0.215. A data pair (beta cap 0, beta cap 1) is plotted at negative (81.06, 0.5229). A dotted square extends between negative 85.44 to negative 76.69 on the horizontal axis, and between 0.5014 and 0.5444 on the vertical axis.
If the two confidence intervals were constructed independently, the actual coverage associated with the confidence region would be [latex](0.95)(0.95) = 0.9025[/latex]. This would be a 90.25% confidence region. If the confidence intervals were constructed independently, then we could simply adjust the coverages of the individual confidence intervals for β0 and β1 to [latex]\sqrt{0.95} \cong 0.9747[/latex] in order to get an exact 95% confidence region for β0 and β1. But the two confidence intervals are constructed from the same data set, and, as seen by the off-diagonal elements in the variance–covariance matrix in Theorem 1.4, the covariance between [latex]\hat \beta_0[/latex] and [latex]\hat \beta_1[/latex] is zero only when [latex]\bar X = 0[/latex]. This is seldom the case in practice. So while the rectangular region in Figure 2.5 is a confidence region, it is not one that we can easily find the associated actual coverage. Some help is provided by the Bonferroni inequality, which states that the actual coverage for the rectangular region is at least [latex]1 - 2 \alpha[/latex], which in this setting is [latex]1 - (2)(0.05) = 0.90[/latex]. Both confidence intervals contain the true value of β0 and β1 with at least 90% confidence, but this is all that can be stated concerning the actual coverage of the rectangular-shaped confidence region.
Since we know that the point estimators for β0 and β1 are only independent in the rare case of [latex]\bar X = 0[/latex] from Theorem 1.4, perhaps a rectangular-shaped confidence region is not appropriate. This is certainly the impression that one gets from the Monte Carlo simulation experiment conducted in Example 1.4. The problem here is that the point estimators [latex]\hat \beta_0[/latex] and [latex]\hat \beta_1[/latex] are typically dependent random variables, which means that a non-rectangular confidence region is appropriate. In an advanced class in regression, you will prove the following result, which is used to determine an exact [latex]{100(1 - \alpha)}\%[/latex] confidence region for β0 and β1.
Let [latex]F_{2, \, n - 2, \, \alpha}[/latex] be the [latex]1 - \alpha[/latex] percentile of the F distribution with 2 and [latex]n - 2[/latex] degrees of freedom. Theorem 2.16 implies that
This inequality can be used to construct an exact [latex]{100(1 - \alpha)}\%[/latex] confidence region for β0 and β1.
The boundary of the confidence region in the [latex](\beta_0, \, \beta_1)[/latex] plane is an ellipse centered at [latex]\big( \hat \beta_0, \, \hat \beta_1 \big)[/latex]. The boundary is found by replacing the inequality in Theorem 2.17 with an equality. The tilt of the ellipse is a function of [latex]\hbox{Cov} \big( \hat \beta_0, \, \hat \beta_1 \big)[/latex], which is [latex]- \bar X S_{XX} / \sigma ^ {\, 2}[/latex] by Theorem 1.4. Notice that [latex]{S_{XX} > 0}[/latex] and [latex]\sigma ^ {\, 2} > 0[/latex] under the simple linear regression model assumptions given in Definition 1.1. If [latex]{\bar X > 0}[/latex], then the covariance between the parameter estimates is negative, which implies that the error associated with the parameter estimates and their true values tends to be in the opposite direction. If [latex]\hat \beta_0 > \beta_0[/latex], for example, then it is more likely that [latex]\hat \beta_1 < \beta_1[/latex]. This is the more common situation in practice. Conversely, if [latex]\bar X < 0[/latex], then [latex]\hbox{Cov} \big( \hat \beta_0, \, \hat \beta_1 \big) > 0[/latex], which implies that the error associated with the parameter estimates and their true values tends to be in the same direction.
The confidence region given in Theorem 2.17 can be plotted for the data pairs [latex]\left( X_1, \, Y_1 \right), \left( X_2, \, Y_2 \right), \ldots \ , \left( X_n, \, Y_n \right)[/latex] using numerical methods. Plotting the boundary of the confidence region in the [latex]( \beta_0, \, \beta_1)[/latex] plane can be performed using a two-dimensional search for points on the boundary. Alternatively, a ray can be extended from [latex]\big( \hat \beta_0, \, \hat \beta_1 \big)[/latex] at a particular angle, and a one-dimensional search can be conducted to find a point on the boundary. The details associated with plotting such a confidence region will be given in one of the examples in the next section.
2.4 The ANOVA Table
In most applications of simple linear regression, the slope of the regression line, β1, is the most critical of the three parameters in the model. The most common statistical test that is performed in a simple linear regression application is testing whether the population slope β1 is zero against the two-tailed alternative:
versus
This choice of H0 and H1 is designed to determine whether the independent variable X is a statistically significant predictor of the dependent variable Y. Rejecting H0 indicates that the independent variable is providing some predictive capability. Although this test can be conducted based on Theorem 2.5, a second test based on the F distribution is introduced in this section and its equivalency to the test based on the t distribution is established. Both tests are exact. In addition, the ANOVA table which was introduced in Section 1.8 will be expanded in this section to include an additional column.
Cochran’s theorem, named after American statistician William Cochran (1909–1980), concerns writing sums of squares of independent and identically distributed [latex]N \kern -0.02em \left( 0, \, \sigma ^ {\, 2} \right)[/latex] random variables as the sum of positive semi-definite quadratic forms of these random variables. Applying his theorem to the simple linear regression model with normal error terms yields the following result.
The second of the three results has already been seen in Theorem 2.2. The first and third results are necessary to derive the F test for the significance of the slope β1, which is given in the following theorem.
The ANOVA table which was first introduced in Section 1.8 can be expanded to include an additional column on the right as shown in Table 2.2. Some computer packages will add yet another column on the right-hand side of the ANOVA table which contains the p-value associated with the F test.
Table 2.2:Basic ANOVA table for simple linear regression.
Source
SS
df
MS
F
Regression
SSR
1
MSR
[latex]MSR / MSE[/latex]
Error
SSE
[latex]n - 2[/latex]
MSE
Total
SST
[latex]n - 1[/latex]
So the F test for the statistical significance of the slope parameter in the regression model with normal error terms begins by computing the test statistic [latex]F = MSR / MSE[/latex]. If [latex]F < F_{1, \, n - 2, \, 1 - \alpha / 2}[/latex] or [latex]F > F_{1, \, n - 2, \, \alpha / 2}[/latex], then H0 is rejected. The ANOVA table will be illustrated in one of the examples in the next section.
To show that the F-test developed here is equivalent to the same test based on the t distribution in Section 2.3.2,
because [latex]MSR = SSR = \hat \beta_1 ^ 2 S_{XX}[/latex] (which is an exercise from Chapter 1), where t is the test statistic for the hypothesis based on Theorem 2.5. Since the square of a t random variable has the F distribution with the appropriate degrees of freedom, the two tests are equivalent.
We do not pursue the F test any further because the test of significance for the slope of the regression line based on the F distribution is less flexible than that based on the t distribution from Section 2.3.2. The test based on the t distribution is superior because (a) it can adapt to one-tailed alternative hypotheses, and (b) it is capable of testing for slopes other than [latex]\beta_1^\star = 0[/latex]. The primary purpose of introducing the F test here is to append the additional column to the right of the ANOVA table and provide an insightful link between regression, which is presented here, and experimental design, which relies heavily on ANOVA tables.
2.5 Examples
This section contains four examples that illustrate the implementation of the simple linear regression modeling techniques that have been developed so far.
The second example illustrates the assessment of the simple linear regression model, point estimation, and interval estimation for a large data set.
The previous example might leave you wondering whether taller (and shorter) women marrying taller (and shorter) men, and having taller (and shorter) children might eventually result in a planet filled with people of more extreme heights. As first noticed by Sir Francis Galton in 1886 and usually known as “regression to the mean,” this will probably not be the case. Consider the right-hand tail of the height distribution. A taller-than-average woman will indeed typically date and marry a taller-than-average man, but the husband’s height, on average, will not fall as far out into the right-hand-tail of his height distribution as the wife’s percentile in her height distribution. Some mathematics associated with the simple linear regression model backs this up. Recall from Definition 1.3 that the coefficient of correlation is
where the sign associated with r is the same as the sign of [latex]\hat \beta_1[/latex]. Theorem 1.9 gave the alternate formula
This can be rewritten as [latex]\hat \beta_1 S_X = r S_Y[/latex], where SX is the sample standard deviation of [latex]X_1, \, X_2, \, \ldots, \, X_n[/latex] and SY is the sample standard deviation of [latex]Y_1, \, Y_2, \, \ldots, \, Y_n[/latex]. The left-hand side of this equation represents the expected increase (or decrease) in the dependent variable for a one standard deviation increase in the independent variable. But since [latex]|r| < 1[/latex] in nearly all applications (the only exception is when all data pairs fall in a line), this standard deviation increase in X will result in less than a standard deviation increase in Y. In the previous example, where [latex]r = 0.763[/latex] was the correlation coefficient between the heights of the wives and their husbands, a standard deviation increase in the height of a wife results in a increase of just [latex]0.763 S_Y[/latex] increase in the height of her husband. Women do tend to marry taller men on average, but the height of their husbands, on average, are at a lesser percentile of the men’s height distribution than the wife’s height percentile.
The next example considers an automotive application of regression which uses speed as an independent variable and stopping distance as a dependent variable.
The fourth and final example concerns a large data set of home sale prices and associated predictors. Real estate platforms, such as Zillow and Trulia, are able to assess home values using a variety of predictors, and one key predictor is illustrated in the final example.
2.6 Exercises
2.1 True or false: An alternative way to express the simple linear regression model with normal error terms is
or
for [latex]i = 1, \, 2, \, \ldots, \, n[/latex].
2.2 Consider a simple linear regression model with normal error terms and population parameters [latex]\beta_0 = 5[/latex], [latex]\beta_1 = 2[/latex], and [latex]\sigma = 2[/latex]. The independent variable assumes the values [latex]x = 1, \, 2, \, \ldots , \, 10[/latex], and [latex]n = 10[/latex] data pairs are collected, one for each potential value of the independent variable.
Conduct a Monte Carlo simulation experiment which determines the shape of the marginal distribution of Y.
How do you think the marginal distribution of Y will change as [latex]\sigma \rightarrow 0[/latex].
How do you think the marginal distribution of Y will change as [latex]\sigma \rightarrow \infty[/latex].
2.3 Show that
2.4 For a simple linear regression model with normal error terms and known value of σ2, give an exact two-sided [latex]{100(1 - \alpha)}\%[/latex] confidence interval for β1.
2.5 Fit the data pairs from the first of the Anscombe’s quartet from Example 2.6 to the simple linear regression model with normal error terms and give point and exact two-sided 95% confidence intervals for the parameters β0, β1, and σ2.
2.6 For what value of the independent variable is the confidence interval for the expected value of the associated dependent variable the narrowest?
2.7 For a simple linear regression model with normal error terms, known value of σ2, and a fixed value Xh in the scope of the model, give an exact two-sided [latex]{100(1 - \alpha)}\%[/latex] confidence interval for [latex]E[ Y_h ] = \beta_0 + \beta_1 X_h[/latex].
2.8 Conduct a Monte Carlo simulation that yields compelling numerical evidence that the confidence interval for [latex]E[Y_h][/latex] from Theorem 2.12 is an exact confidence interval for the following parameter settings: [latex]n = 10[/latex], [latex]\beta_0 = 1[/latex], [latex]\beta_1 = 1 / 2[/latex], [latex]\sigma ^ {\, 2} = 1[/latex], [latex]X_h = 3[/latex], [latex]\alpha = 0.05[/latex], and [latex]X_i = i[/latex] for [latex]i = 1, \, 2, \, \ldots, \, 10[/latex].
2.10 True or false: The width of a 95% confidence interval for [latex]E[Y_h][/latex] shrinks to zero in the limit as [latex]n \rightarrow \infty[/latex].
2.11 True or false: The width of a 95% prediction interval for [latex]Y_h^\star[/latex] shrinks to zero in the limit as [latex]n \rightarrow \infty[/latex].
2.12 The R data frame named longley contains seven macroeconomical variables from the United States collected from 1947 to 1962. Use the number of people employed to predict the gross national product (GNP) measured in constant 1954 dollars. Assuming that the simple linear regression model with normal error terms is appropriate,
make a scatterplot of the [latex]n = 16[/latex] data pairs and superimpose the regression line,
make a plot of the standardized residuals,
make a QQ plot of the residuals,
conduct the Shapiro–Wilk test for normality of the residuals,
give a point estimate and an exact 95% confidence interval for the slope β1,
give a point estimate and an exact 95% confidence interval for the intercept β0,
give a point estimate and an exact 95% confidence interval for the mean value of the GNP, [latex]E \left[ Y_h \right][/latex], when [latex]X_h = 65[/latex] million people are employed, and
give a point estimate and an exact 95% prediction interval for the GNP, [latex]Y_h^\star[/latex], associated with a new data pair when [latex]X_h = 65[/latex] million people are employed.
2.13 Under the simple linear regression model with normal error terms and parameters estimated from the data pairs [latex]\left( X_1, \, Y_1 \right), \, \left( X_2, \, Y_2 \right), \, \ldots , \, \left( X_n, \, Y_n \right)[/latex], the exact two-sided [latex]{100(1 - \alpha)}\%[/latex] prediction interval for [latex]Y_h^*[/latex] given in Theorem 2.15 is appropriate for a single new observation associated with a fixed value of the independent variable Xh. What if there are m new observations? In this case, an exact two-sided [latex]{100(1 - \alpha)}\%[/latex] prediction interval for the mean response [latex]Y_h^*[/latex] is
for [latex]Y_h^\star[/latex], where
and Xh is a fixed value of the independent variable within the scope of the simple linear regression model. Find a 95% prediction interval for the heights data pairs (using the wife’s height as the independent variable) from the PBImisc package from Example 2.7 with [latex]m = 4[/latex] and [latex]X_h = 150[/latex].
2.14 For the prediction interval for the population mean of the average of m new observations at a single setting of the independent variable Xh given in the previous question, what does the prediction interval collapse to in the limit as [latex]m \rightarrow \infty[/latex].
2.15 Consider the built-in data frame in R named trees, which contains data pairs of diameters (which will be the independent variable and is erroneously labeled Girth in the data frame) measured at 4 feet 6 inches above the ground and associated volumes (which will be the dependent variable) for [latex]n = 31[/latex] felled black cherry trees. Assuming that the simple linear regression model with normal error terms is appropriate, perform the following statistical inference procedures.
Plot the data pairs and the associated regression line.
Find a point estimate and an exact 95% confidence interval for β1. Interpret the point estimate and the confidence interval.
Find a point estimate and an exact 95% confidence interval for the mean volume, [latex]E \left[ Y_h \right][/latex], when the diameter is [latex]X_h = 20[/latex] inches.
Find a point estimate and an exact 95% prediction interval for the volume, [latex]Y_h^\star[/latex], associated with a new data pair with a diameter of [latex]X_h = 20[/latex] inches.
Graph all values of the exact 95% confidence interval bounds for the expected volume for all diameters in the scope of the simple linear regression model. Also, graph all values of the exact 95% prediction interval bounds for the volume for a 32nd tree for all diameters in the scope of the simple linear regression model.
2.16 Plot a 95% confidence region for the data pairs in the cars data set under a simple linear regression model with normal error terms
using numerical methods, and
using the ellipse function from the ellipse package.
Include the maximum likelihood estimates for [latex]\hat \beta_0[/latex] and [latex]\hat \beta_1[/latex] and 95% confidence intervals for β0 and β1 on your plot.
2.17 Conduct a Monte Carlo simulation that provides convincing numerical evidence that the confidence region given in Theorem 2.17 is an exact confidence region for the following parameter settings: [latex]n = 10[/latex], [latex]\beta_0 = 1[/latex], [latex]\beta_1 = 1 / 2[/latex], [latex]\sigma ^ {\, 2} = 1[/latex], [latex]\alpha = 0.05[/latex], and [latex]X_i = i[/latex] for [latex]i = 1, \, 2, \, \ldots, \, 10[/latex].
2.18 Consider the simple linear regression model with normal error terms applied to the first set of [latex]n = 11[/latex] data pairs from Anscombe’s quartet from Example 2.6. Show that the p-values are identical for testing
versus
using
the F test based on using the test statistic which is the ratio of MSR to MSE, and
the t test based on using the test statistic [latex]\hat \beta_1 / \sqrt{MSE / S_{XX}}[/latex].
2.19Figures 1.24, 1.25, and 1.26 depict three examples of extreme cases for SSE, SSR, and SST for [latex]n = 7[/latex] data pairs. Assuming the simple linear regression model with normal error terms is an appropriate model,
plot and label the potential points associated with the extreme cases when SSR is plotted on the horizontal axis and SSE is plotted on the vertical axis, and
on this same graph, shade the area associated with rejecting H0 at level of significance at [latex]\alpha = 0.05[/latex] for the statistical test
versus
2.20 Plot a power function for the Ftest for testing
versus
for [latex]n = 10[/latex], [latex]\beta_0 = 1[/latex], [latex]\sigma ^ {\, 2} = 1[/latex], [latex]\alpha = 0.05[/latex], and [latex]X_i = i[/latex], for [latex]i = 1, \, 2, \, \ldots, \, n[/latex]. You may use Monte Carlo simulation or the noncentral F distribution to generate the power function. Allow [latex]\beta_1[/latex] to vary from [latex]-1[/latex] to 1 in the plot.
2.21 Make plots of the standardized residuals for the four data sets from Anscombe’s quartet given in Example 2.6.
2.22 The confidence interval for [latex]E[Y_h][/latex] given in Theorem 2.12 is meaningful for a fixed value of the independent variable Xh. What if a confidence band that contains the entire regression line with a prescribed probability is desired. The Working–Hotelling [latex]{100(1 - \alpha)}\%[/latex] confidence band for the regression line at any level Xh is given by
under the simple linear regression model with normal error terms, where
Plot a 95% confidence band for the heights data pairs from Example 2.7.